
A walk-through of creating a Netmon parser in the context of a real case
This is an archive post of content I wrote for the NTDebugging Blog on MSDN. Since the MSDN blogs are being retired, I’m transferring my posts here so they aren’t lost. The post has been back-dated to its original publication date.
As is obvious to frequent readers of our blog, our team logs a lot of time in our debugger of choice (for some, windbg, for others, kd). However, a debugger is not always the best tool for the job, and sometimes even the best tool has limitations. I found this to especially true when working a few Internet Printing Protocol (IPP) cases recently.
Probably the biggest challenge of many IPP cases is the mixed environments you usually find IPP running in. The benefit customers see in IPP over other print providers is it works natively or with minimal configuration on Windows, Mac, and Linux clients. This makes it popular in places like college computer labs, where there isn’t one standard client system. Unfortunately, this also means that we can’t really debug both sides of the communication when something goes wrong.
In a recent case, a customer was having problems printing from their Windows Vista clients to a Linux Common Unix Printing System (CUPS) IPP server. If the CUPS server was set to allow anonymous connections, everything worked perfectly. When the administrator enabled authentication, he found that most print jobs failed to print. After a bit more testing, he found that small jobs (perhaps a page of printed text) worked fine, but larger, multi-page documents failed.
For situations like this, I prefer to use a network trace to get a feeling for where the problem is occurring. The problem was – IPP wasn’t one of the protocols built in to Netmon (and I find Wireshark’s IPP parser to not always work well – especially with Windows clients/servers). I decided that the amount of time it would take to decode the traffic by hand could be better spent creating a Netmon IPP parser that I could use every time I ran into one of these issues.
One of the great things about Netmon is you can view the source of every included parser. This was a big help, as I hadn’t written a parser before. [Note: all steps noted are written using Netmon 3.4.There might be slight differences in NM3.3.] To do this, open Netmon and click the Parsers tab. Under Object View, expand parser files and double click any of the .npl files. The source will appear on the right.
The language for Netmon parsers is similar to C++, with a limited set of statements. These are all documented in the Netmon help file, but the ones I found useful are described below. To begin, I started by defining a number of tables. The basic idea of a table is to provide a way to convert a value to a string. For example, one field in an IPP packet is the status of a printer, which is represented by an integer. In order to allow Netmon to show printer states in a readable form, I created a table to convert the values as seen in Figure 1 below.
Table IPPPrinterState //2911-4.4.11
{
switch(value)
{
case 3 : "idle";
case 4 : "processing";
case 5 : "stopped";
default : "Unknown Code";
}
}Figure 1: Netmon Table
Each table is defined with the Table keyword, followed by a name for the table. (It may optionally be followed by a list of parameters, which I’ll use later. In this case, I added a comment that specified which RFC and section this information comes from.) A table consists of a switch statement with a case for each value, and a default for all other cases, much like other programming languages. I created tables like IPPPrinterState for each field that could be represented in an IPP packet from information I found in each of IPP’s RFCs.
Once the tables were complete, I moved on to creating the Protocol portion of the parser. This section of the code provides the logic that iterates through a packet and calls the tables for the appropriate data. This section starts with either the RegisterBefore or RegisterAfter keyword. These are used to determine how your parser is called. Essentially, Netmon takes all of the parsers it has, and compiles them into one continuous binary (.npb) and registration tells Netmon where your parser fits. For my case, I used the following registration code.
[ RegisterAfter (HTTPPayloadData.OCSP, Ipp, Property.HTTPContentType.Contains("application/ipp")) ]This tells Netmon that, when compiling the parser, it should insert my code right after the code for the OCSP protocol in its HTTPPayloadData parser, my protocol should be called IPP, and it should enter my code path if the HTTP Payload is of content type “application/ipp”. This allows my parser to work a bit differently than the Wireshark IPP parser – Wireshark uses a port number (631) to identify IPP traffic, whereas my code looks at HTTP content types. The advantage of this, for me, is that Windows servers use port 80 for IPP by default, not 631, so in cases with a Windows IPP server, this parser should correctly identify the packets. You may be wondering how or why I chose to register after OCSP. Basically, I knew I needed my code to be registered in the section of code where HTTP does its payload content type processing. So I opened up HTTP’s parser, and searched for the content type analysis. OCSP was the first protocol I found in HTTP’s content type logic, so I used that as the place to insert my protocol.
After the registration comes the Protocol statement. I chose the following.
Protocol IPP = FormatString("Status/OpCode = %s", IPPOperationsSupported(OpID))This names my protocol IPP and specifies that I want the description of the protocol to display the IPP status code. This way, a user doesn’t need to drill down to find out if this is a print job or a printer status request. You’ll notice FormatString is a function in Netmon that is similar to printf. In this case, I am passing a variable (OpID, which is defined lower in my code) to my IPPOperationsSupported table to determine what this OpCode means. Before I had a parser, I would need to look up the operations supported values in the IPP RFC for each packet I examined.
Next is the body of the protocol. Basically, this consists of a series of fields (like variables) that define how a packet is laid out. Creating a field is similar to declaring a variable in C++. You start by choosing a data type that matches the size of the data in the packet and provide a name for that field. For example, Figure 2 shown below contains the first seven lines of my Protocol.
struct Version = FormatString("%i.%i", Major, Minor)
{
INT8 Major;
INT8 Minor;
}
INT16 OpId = FormatString("%s (0x%X)", IPPOperationsSupported(this), this);
INT32 RequestId;Figure 2: Code in the protocol block
The IPP specification states that all packets begin with two 8-bit values, the first value specifies the major protocol version in use, and the second value specifies the minor. In this case, I wrapped both in a struct so Netmon will display them as “Version: 1.0”, instead of separately as “Major: 1” “Minor: 0” on two lines. After the version is a 16-bit field that specifies the operation requested (for example, print-job or get-printer-state). I choose to display this value by looking it up in the IPPOperationsSupported table, then printing it as the string, followed by the hex value (e.g. “Get-Printer-Attributes (0xB)”). The ‘this’ keyword simply uses the value of the current field, which in this case is the OpId. Even though Netmon parses through the packet sequentially, this kind of use of a Field before its value is retrieved is allowed. Finally, I set the RequestId field, which is a 32-bit int value. Since this field is just a transaction ID for this conversation, I don’t need to do any formatting to it.
After that, things got a little more complicated. IPP’s structure allows for a variable number of attribute groups, each of which can contain a variable number of attributes. For example, in response to the request “Get-Printer-Attributes” from the client, the server responds with the Printer Attributes group, which contains a number of attributes like printer-state, queued-job-count, and so on. First, I needed to deal with the attribute groups in a loop until I’d read each one. IPP specifies that the end of the attribute groups is specified with the value of 0x03, so I wrote a while loop to create attribute groups until FrameData[FrameOffset] is equal to 3 (See Figure 3 below). FrameData and FrameOffset are special values provided by Netmon. FrameData is an array of the entire contents of the frame, and FrameOffset is Netmon’s current location in the packet. I use this instead of declaring a field here because referencing FrameData[FrameOffset] does not advance the parser frame location. This is important because I want to consume that value further down.
Inside that loop, I declared another struct that contains an attribute group. Much like the Protocol IPP line above, we reference a field here that will be declared lower down. This line does not advance the FrameOffset, since we don’t declare a field here. The first line of this struct is the field declaration line that finally consumes the attribute group tag. Below that is another While loop to process all attributes in the attribute group. IPP differentiates between attributes and attribute groups by making all attribute group identifiers smaller than 0x10, and all attribute identifiers 0x10 or higher. I use this as the condition for my loop. Finally, I declare an Attribute struct inside this loop. This struct is displayed after looking up how to properly print based on the Attribute Name and Value in the AttribDisplayTable.
IPP declares attributes as an 8-bit type identifier (int, bool, string, etc.), a 16-bit int specifying the attribute name’s length, the name (a string), a 16-bit in value length, and a value. Since I want to look up the value in various tables, depending on the Attribute Name, I store the Attribute Name as “AttName” in a property. This way, I can continue to reference it while processing continues. Properties are declared in brackets just above the field they will store. In my case, I prepend the ‘Post.’ evaluation keyword to the property name. This instructs Netmon to use the end result of the next line as its value, but before advancing the FrameOffset. I do this again for the actual value, which I call Val. If I did not use the Post evaluation keyword, Val would contain the unsigned int32 value of printer state, instead of the formatted string result I get by looking up printer state in its table.
While [FrameData[FrameOffset] != 0x03]
{
struct AttributeGroup = FormatString("%s", IPPTags(TagGroup))
{
INT8 TagGroup = FormatString("%s (0x%X)", IPPTags(this), this);
While [FrameData[FrameOffset] >= 0x10]
{
struct Attribute = AttribDisplayTable(AttName, Val)
{
INT8 Type = FormatString("%s (0x%X)", IPPTags(this), this);
INT16 NameLength;
[Post.AttName]
AsciiString(NameLength) AttributeName;
INT16 ValueLength;
switch(AttName)
{
case "printer-state" :
[Post.Val]
UINT32 PrinterState = FormatString("%s (0x%X)", IPPPrinterState(this),this);
...Figure 3: Loops in protocol block
My case statements continue like printer-state for all possible attributes of IPP. At the very end of the protocol block, after I’ve closed my switch, structs, and whiles, I have one more line, which consumes any data remaining in the packet. This would contain document data if the packet was a print job, and is required so all the packet data is consumed before Netmon moves on to the next packet. That line is:
BLOB (FrameLength – FrameOffset) Data;
As you can see, it is a binary blob data type, set to the size of the frame, less our current location.
Finally, after my Protocol block, I needed to define my own data type. IPP defines its own data format to specify printer uptime, so I created a data type for it as shown below in Figure 4.
//Uptime format spec
Number UPTIME
{
Size = 4;
DisplayFormat = (this != 0) ? FormatString("%i days %02i:%02i:%02i (%i seconds)",
(this/86400), //Days
(this-((this/86400)*86400))/3600, //Hours
(this-(((this/86400)*86400)+(((this-((this/86400)*86400))/3600)*3600)))/60, //Minutes
(this%60), //Seconds
this) : "0"
}Figure 4: Custom data type
The first line of Figure 4 specifies this will be a data type composed of numeric data named UPTIME. Size specifies how many bytes the type uses. DisplayFormat is what Netmon displays for this type. In this case, I use the x ? y : z syntax. Netmon doesn’t have if/then/else keywords, but instead uses this ternary operator. I use a special case for 0 since it seems to be a common return value in the traces I’ve looked at, and having ‘Uptime: 0 days 00:00:00 (0 seconds)’ seemed excessive.
Figures 5 and 6 below show what the result looks like in Netmon.
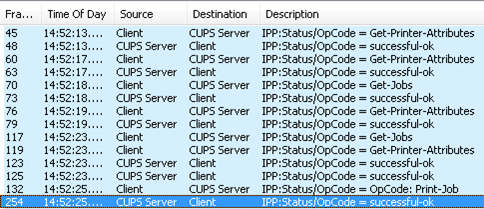
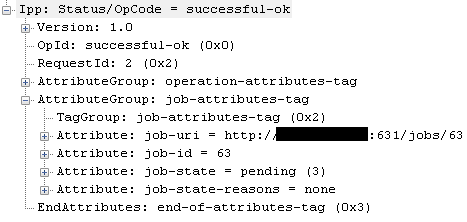
So what did the trace show? Windows attempts to send IPP requests with no authentication first, then if it receives an access denied, retries with authentication. This is by design, as the IPP server replies with the authentication types it supports in the access denied message. In the case of print jobs that are too large to fit in a single packet, IPP’s spec allows servers to either issue the access denied message as soon as it receives the first packet, or after it has received the entire job. It turns out that the IPP Print Provider on Windows was designed to send the entire job before listening for a response, so it missed the access denied message that CUPS sent after it received the first packet. See http://support.microsoft.com/kb/976988/ [New link https://support.microsoft.com/en-us/topic/you-may-be-unable-to-print-to-an-ipp-print-queue-in-windows-7-or-in-windows-server-2008-r2-44a0f58a-4894-f98c-4a82-ed66eeb84ded] for related information. Want a copy of the IPP parser? It will be included in a future release of the Netmon Parser Update [Archived at https://codeplexarchive.org/project/NMParsers, code also shown below].
I hope this post have given you a better idea of how Netmon works, how IPP works, and helps if you ever need to write a parser for your protocol.
-Matt Burrough
//# (c) 2010 Outercurve Foundation
//#
//# Title: Internet Printing Protocol v1.1
//#
//# Details:
//#
//# Public References: RFC 2910, 2911, 3380, 3381, 3382, 3995, 3996, 3998, pwg5100.1, pwg5100.5, pwg5100.7, pwg5100.8
//#
//# Comments:
//#
//# Revision Class and Date:Major, 07/28/2011
//#
//####
[ RegisterAfter(HTTPPayloadData.OCSP, IPP, Property.HTTPContentType.Contains("application/ipp")) ]
Protocol IPP = FormatString(Property.HttpIsRequest == 0x1 ? "OperationID = " + IPPOperationsID(OperationID):"StatusCode = " + IPPStatusCodes(StatusCode))
{
[ MaxLoopCount = 1 ]
while [ FrameData[ FrameOffset ]==0x01 && FrameData[ FrameOffset + 1 ] <= 0x01 ] // Only support IPP v1.0/1.1 (latest version released)
{
struct Version = FormatString("%i.%i", Major, Minor)
{
INT8 Major;
INT8 Minor;
}
switch
{
case Property.HttpIsRequest == 0x1:
UINT16 OperationID = FormatString("%s (0x%X)", IPPOperationsID(this), this);
case Property.HttpIsResponse == 0x1:
UINT16 StatusCode = FormatString("%s (0x%X)", IPPStatusCodes(this), this);
default:
ReportParserError(ParserErrorProtocolClassWindows, "IPP", "Unknown Message" ) MessageError;
}
INT32 RequestId;
While [ FrameData [ FrameOffset ] != 0x03 ]
{
struct AttributeGroup = FormatString("%s", IPPTags(TagGroup))
{
INT8 TagGroup = FormatString("%s (0x%X)", IPPTags(this), this);
While [FrameData[FrameOffset] >= 0x10]
{
struct Attribute = FormatString("%s %s %s", AttName, DrawEquals(ValueLength), AttribDisplayTable(AttName, Ret))
{
INT8 Type = FormatString("%s (0x%X)", IPPTags(this), this);
INT16 NameLength;
[Post.AttName]
AsciiString(NameLength) AttributeName;
INT16 ValueLength;
[Post.Val]
ValueStr(AttName, Type, ValueLength) Value = AttribDisplayTable(AttName, Ret);
while [FrameData[FrameOffset + 1] == 0 && FrameData[FrameOffset + 2] == 0]
{
struct AdditionalAttribute = AdditionalValue.ToString
{
INT8 AdditionalType = FormatString("%s (0x%X)", IPPTags(this), this);
INT16 AdditionalNameLength;
INT16 AdditionalValueLength;
[PostAfter.Ret = "..."]
ValueStr(AttName, AdditionalType, AdditionalValueLength) AdditionalValue = AttribDisplayTable(AttName, Ret);
}
}
}
}
}
}
INT8 EndAttributes = FormatString("%s (0x%X)", IPPTags(this), this); // end-of-attribues tag
}
BLOB (FrameLength - FrameOffset) Data; // For things like print job binary data
}
// Tables of value codes from IPP RFCs
Table IPPTags(value) //2910-3.5
{
switch(value)
{
// Delimiter Tags
case 0x00 : "reserved";
case 0x01 : "operation-attributes-tag";
case 0x02 : "job-attributes-tag";
case 0x03 : "end-of-attributes-tag";
case 0x04 : "printer-attributes-tag";
case 0x05 : "unsupported-attributes-tag";
case 0x06 : "subscription-attributes-tag";
case 0x07 : "event-notification-attributes-tag";
case 0x09 : "document-attributes-tag"; // pwg5100.5
// Value Tags
case 0x10 : "unsupported";
case 0x11 : "reserved";
case 0x12 : "unknown";
case 0x13 : "no-value";
case 0x15 : "not-settable"; // 3380
case 0x16 : "delete-attribute";
case 0x17 : "admin-define";
// Types
case 0x20 : "reserved-generic-integer";
case 0x21 : "integer";
case 0x22 : "boolean";
case 0x23 : "enum";
// OctectString
case 0x30 : "octetString with an unspecified format";
case 0x31 : "dateTime";
case 0x32 : "resolution";
case 0x33 : "rangeOfInteger";
case 0x34 : "begCollection";
case 0x35 : "textWithLanguage";
case 0x36 : "nameWithLanguage";
case 0x37 : "endCollection";
// Character Strings
case 0x40 : "reserved-generic-char-str";
case 0x41 : "textWithoutLanguage";
case 0x42 : "nameWithoutLanguage";
case 0x43 : "reserved";
case 0x44 : "keyword";
case 0x45 : "uri";
case 0x46 : "uriScheme";
case 0x47 : "charset";
case 0x48 : "naturalLanguage";
case 0x49 : "mimeMediaType";
case 0x4A : "memberAttrName"; // 3382
case 0x7F : "Extension";
default : "Unknown or Reserved Tag";
}
}
Table IPPFinishing(value) // 2911-4.2.6
{
switch(value)
{
case 3 : "none";
case 4 : "staple";
case 5 : "punch";
case 6 : "cover";
case 7 : "bind";
case 8 : "saddle-stitch";
case 9 : "edge-stitch";
case 10 : "fold"; // pwg5100.1
case 11 : "trim";
case 12 : "blae";
case 13 : "booklet-maker";
case 14 : "jog-offset";
case 20 : "staple-top-left";
case 21 : "staple-bottom-left";
case 22 : "staple-top-right";
case 23 : "staple-bottom-right";
case 24 : "edge-stitch-left";
case 25 : "edge-stitch-top";
case 26 : "edge-stitch-right";
case 27 : "edge-stitch-bottom";
case 28 : "staple-dual-left";
case 29 : "staple-dual-top";
case 30 : "staple-dual-right";
case 31 : "staple-dual-bottom";
case 50 : "bind-left";
case 51 : "bind-top";
case 52 : "bind-right";
case 53 : "bind-bottom";
default : "Unknown Code";
}
}
Table IPPOrientationRequested(value) // 2911-4.2.10
{
switch(value)
{
case 3 : "portrait";
case 4 : "landscape";
case 5 : "reverse-landscape";
case 6 : "reverse-portrait";
default : "Unknown Code";
}
}
Table IPPPrintQuality(value) // 2911-4.2.13
{
switch(value)
{
case 3 : "draft";
case 4 : "normal";
case 5 : "high";
default : "Unknown Code";
}
}
Table IPPJobCollation(value) // 3381-4.1
{
switch(value)
{
case 1 : "Other";
case 2 : "Unknown";
case 3 : "Uncollated-Sheets";
case 4 : "Collated-Documents";
case 5 : "Uncollated-Documents";
default : "Unknown Code";
}
}
Table IPPJobState(value) // 2911-4.3.7
{
switch(value)
{
case 3 : "pending";
case 4 : "pending-held";
case 5 : "processing";
case 6 : "processing-stopped";
case 7 : "canceled";
case 8 : "aborted";
case 9 : "completed";
default : "Unknown Code";
}
}
Table IPPDocumentState(value) // pwg5100.5
{
switch(value)
{
case 3 : "Pending";
case 5 : "Processing";
case 7 : "Canceled";
case 8 : "Aborted";
case 9 : "Completed";
default : "Unknown State";
}
}
Table IPPPrinterState(value) // 2911-4.4.11
{
switch(value)
{
case 3 : "idle";
case 4 : "processing";
case 5 : "stopped";
default : "Unknown Code";
}
}
Table IPPUnits(value) // 2911-4.1.15
{
switch(value)
{
case 3 : "dpi";
case 4 : "dpcm";
}
}
Table IPPOperationsID(value) // 2911-4.4.15
{
switch(value)
{
// Op Codes
case 0x0000 : "reserved";
case 0x0001 : "reserved";
case 0x0002 : "Print-Job";
case 0x0003 : "Print-URI";
case 0x0004 : "Validate-Job";
case 0x0005 : "Create-Job";
case 0x0006 : "Send-Document";
case 0x0007 : "Send-URI";
case 0x0008 : "Cancel-Job";
case 0x0009 : "Get-Job-Attributes";
case 0x000A : "Get-Jobs";
case 0x000B : "Get-Printer-Attributes";
case 0x000C : "Hold-Job";
case 0x000D : "Release-Job";
case 0x000E : "Restart-Job";
case 0x000F : "reserved";
case 0x0010 : "Pause-Printer";
case 0x0011 : "Resume-Printer";
case 0x0012 : "Purge-Jobs";
case 0x0013 : "Set-Printer-Attributes"; // 3380
case 0x0014 : "Set-Job-Attributes";
case 0x0015 : "Get-Printer-Supported-Values";
case 0x0016 : "Create-Pritner-Subscriptions"; // 3995
case 0x0017 : "Create-Job-Subscriptions";
case 0x0018 : "Get-Subscription-Attributes";
case 0x0019 : "Get-Subscriptions";
case 0x001A : "Renew-Subscription";
case 0x001B : "Cancel-Subscription";
case 0x001C : "Get-Notifications"; // 3996
case 0x0021 : "Get-Client-Printer-Support-Files"; // http://www.ietf.org/proceedings/48/I-D/ipp-install-00.txt
case 0x0022 : "Enable-Printer"; // 3998
case 0x0023 : "Disable-Printer";
case 0x0024 : "Pause-Printer-After-Current-Job";
case 0x0025 : "Hold-New-Jobs";
case 0x0026 : "Release-Held-New-Jobs";
case 0x0027 : "Deactivate-Printer";
case 0x0028 : "Activate-Printer";
case 0x0029 : "Restart-Printer";
case 0x002A : "Shutdown-Printer";
case 0x002B : "Startup-Printer";
case 0x002C : "Reprocess-Job";
case 0x002D : "Cancel-Current-Job";
case 0x002E : "Suspend-Current-Job";
case 0x002F : "Resume-Job";
case 0x0030 : "Promote-Job";
case 0x0031 : "Schedule-Job-After";
case 0x0033 : "Cancel-Document"; // pwg5100.5
case 0x0034 : "Get-Document-Attributes";
case 0x0035 : "Get-Documents";
case 0x0036 : "Delete-Document";
case 0x0037 : "Set-Document-Attributes";
// Vendor-Specific codes (0x4000-0xFFFF) (http://www.pwg.org/ipp/opcodes/ippopcodes.html)
case 0x4000 : "Microsoft Specific Auth";
case 0x4001 : "CUPS-Get-Default"; // http://www.cups.org/documentation.php/spec-ipp.html
case 0x4002 : "CUPS-Get-Printers";
case 0x4003 : "CUPS-Add-Modify-Printer";
case 0x4004 : "CUPS-Delete-Printer";
case 0x4005 : "CUPS-Get-Classes";
case 0x4006 : "CUPS-Add-Modify-Class";
case 0x4007 : "CUPS-Delete-Class";
case 0x4008 : "CUPS-Accept-Jobs";
case 0x4009 : "CUPS-Reject-Jobs";
case 0x400A : "CUPS-Set-Default";
case 0x400B : "CUPS-Get-Devices";
case 0x400C : "CUPS-Get-PPDs";
case 0x400D : "CUPS-Move-Job";
case 0x400E : "CUPS-Authenticate-Job";
case 0x400F : "CUPS-Get-PPD";
case 0x4010 : "Peerless Systems Specific";
case 0x401A : "novell-list-printers"; // https://www1.ietf.org/mail-archive/text/ipp/2008-03.mail
case 0x401B : "novell-list-drivers";
case 0x401C : "novell-mgmt-interface";
case 0x401D : "novell-resource-add";
case 0x401E : "novell-resource-list";
case 0x401F : "novell-resource-delete";
case 0x4020 : "novell-resource-download";
case 0x4021 : "novell-get-driver-profile";
case 0x4022 :
case 0x4023 :
case 0x4024 :
case 0x4025 : "Novell Specific";
case 0x4026 : "Xerox Specifc";
case 0x4027 : "CUPS-Get-Document";
default : "Unknown Operations ID";
}
}
Table IPPStatusCodes(value) // 2911-4.4.15
{
switch
{
// Status Codes
// 0x0000:0x00FF - "successful"
case value == 0x0000 : "successful-ok";
case value == 0x0001 : "successful-ok-ignored-or-substituted-attributes";
case value == 0x0002 : "successful-ok-conflicting-attributes";
case value == 0x0003 : "successful-ok-ignored-subscriptions";
case value == 0x0005 : "successful-ok-too-many-events";
case value == 0x0007 : "successful-ok-events-complete";
case value >= 0x0100 && value <= 0x01FF: "informational";
case value >= 0x0300 && value <= 0x03FF: "redirection";
// 0x0400:0x04FF - "client-error"
case value == 0x0400 : "client-error-bad-request";
case value == 0x0401 : "client-error-forbidden";
case value == 0x0402 : "client-error-not-authenticated";
case value == 0x0403 : "client-error-not-authorized";
case value == 0x0404 : "client-error-not-possible";
case value == 0x0405 : "client-error-timeout";
case value == 0x0406 : "client-error-not-found";
case value == 0x0407 : "client-error-gone";
case value == 0x0408 : "client-error-request-entity-too-large";
case value == 0x0409 : "client-error-request-value-too-long";
case value == 0x040A : "client-error-document-format-not-supported";
case value == 0x040B : "client-error-attributes-or-values-not-supported";
case value == 0x040C : "client-error-uri-scheme-not-supported";
case value == 0x040D : "client-error-charset-not-supported";
case value == 0x040E : "client-error-conflicting-attributes";
case value == 0x040F : "client-error-compression-not-supported";
case value == 0x0410 : "client-error-compression-error";
case value == 0x0411 : "client-error-document-format-error";
case value == 0x0412 : "client-error-document-access-error";
case value == 0x0413 : "client-error-attributes-not-settable"; // 3380
case value == 0x0414 : "client-error-ignored-all-subscriptions"; // 3995
case value == 0x0415 : "client-error-too-many-subscriptions";
case value == 0x0417 : "clnt-err-client-print-support-file-not-found"; // http://www.ietf.org/proceedings/48/I-D/ipp-install-00.txt
//0x0500:0x05FF - "server-error"
case value == 0x0500 : "server-error-internal-error";
case value == 0x0501 : "server-error-operation-not-supported";
case value == 0x0502 : "server-error-service-unavailable";
case value == 0x0503 : "server-error-version-not-supported";
case value == 0x0504 : "server-error-device-error";
case value == 0x0505 : "server-error-temporary-error";
case value == 0x0506 : "server-error-not-accepting-jobs";
case value == 0x0507 : "server-error-busy";
case value == 0x0508 : "server-error-job-canceled";
case value == 0x0509 : "server-error-multiple-document-jobs-not-supported";
case value == 0x050A : "server-error-printer-is-deactivated"; // 3398
case value == 0x050B : "server-error-too-many-jobs"; // pwg5100.7
case value == 0x050C : "server-error-too-many-documents";
default : "Unknown Status Code";
}
}
Table DrawEquals(ValLen)
{
switch(ValLen)
{
case 0 : "";
default : "=";
}
}
// Tables for displaying attribute summaries
Table AttribDisplayTable(Attrib, Val)
{
switch(val)
{
case "..." : // Don't try to format multi-value attributes
FormatString("%s", Val);
default:
AttribFormatTable(Attrib, Val);
}
}
Table AttribFormatTable(Attrib, Val)
{
switch(Attrib)
{
case "printer-state" :
FormatString("%s (%u)", IPPPrinterState(Val),Val);
case "finishings" :
case "finishings-actual" : // pwg5100.8
FormatString("%s (%u)", IPPFinishing(Val),Val);
case "orientation-requested" :
case "orientation-requested-actual" : // pwg5100.8
FormatString("%s (%u)", IPPOrientationRequested(Val),Val);
case "print-quality" :
case "print-quality-actual" : // pwg5100.8
FormatString("%s (%u)", IPPPrintQuality(Val),Val);
case "job-state" :
FormatString("%s (%u)", IPPJobState(Val),Val);
case "job-collation-type" : // 3381
FormatString("%s (%u)", IPPJobCollation(Val),Val);
case "document-state" :
FormatString("%s (%u)", IPPDocumentState(Val),Val);
case "operations-supported" :
FormatString("%s (%u)", IPPOperationsID(Val),Val);
case "printer-is-accepting-jobs" :
case "multiple-document-jobs-supported" :
case "color-supported" :
(Val!=0) ? FormatString("TRUE (0x01)") : FormatString("FALSE (0x00)");
case "time-at-creation" :
case "time-at-processing" :
case "time-at-completed" :
case "job-printer-up-time" :
case "printer-up-time" :
FormatString("%i days %02i:%02i:%02i (%i seconds)",
(Val/86400), // Days
(Val-((Val/86400)*86400))/3600, // Hours
(Val-(((Val/86400)*86400)+(((Val-((Val/86400)*86400))/3600)*3600)))/60, // Minutes
(Val%60),
Val);
default :
FormatString("%s", Val);
}
}
// Uptime format spec
Number UPTIME
{
Size = 4;
DisplayFormat = FormatString("%i days %02i:%02i:%02i (%i seconds)",
(this / 86400), // Days
(this - ((this / 86400) * 86400)) / 3600, // Hours
(this - (((this / 86400) * 86400) + (((this - ((this / 86400) * 86400)) / 3600) * 3600))) / 60, // Minutes
(this % 60), // Seconds
this) // Total secs
}
struct ValueStr(AttName, Type, ValueLength) = Ret
{
switch(AttName)
{
case "printer-state" :
[Ret]
UINT32 PrinterState = FormatString("%s (%u)", IPPPrinterState(this),this);
case "finishings" :
case "finishings-actual" : // pwg5100.8
[Ret]
UINT32 Finishings = FormatString("%s (%u)", IPPFinishing(this),this);
case "orientation-requested" :
case "orientation-requested-actual" : // pwg5100.8
[Ret]
UINT32 Orientation = FormatString("%s (%u)", IPPOrientationRequested(this),this);
case "print-quality" :
case "print-quality-actual" : // pwg5100.8
[Ret]
UINT32 PrintQuality = FormatString("%s (%u)", IPPPrintQuality(this),this);
case "job-state" :
[Ret]
UINT32 JobState = FormatString("%s (%u)", IPPJobState(this),this);
case "job-collation-type" : // 3381
[Ret]
UINT32 JobCollation = FormatString("%s (%u)", IPPJobCollation(this),this);
case "document-state" :
[Ret]
UINT32 DocumentState = FormatString("%s (%u)", IPPDocumentState(this),this);
case "operations-supported" :
[Ret]
UINT32 OperationsSupported = FormatString("%s (%u)", IPPOperationsID(this),this);
case "time-at-creation" :
case "time-at-processing" :
case "time-at-completed" :
case "job-printer-up-time" :
case "printer-up-time" :
[Ret]
UPTIME TimeValue;
default :
switch(Type)
{
case 0x20 :
[Ret]
INT32 ReservedIntValue;
case 0x21 :
[Ret]
INT32 IntValue;
case 0x22 :
[Ret]
BOOLEAN BoolValue;
case 0x23 :
[Ret]
UINT32 EnumValue;
// OctectString
case 0x31 : //2911 4.1.14 --> RFC1903
[Ret]
struct DateAndTime = FormatString("%u-%u-%u,%u:%u:%u.%u,%c%u:%u", Year, Month, Day, Hour, Minute, Second, DeciSec, DUTC, HUTC, MUTC)
{
// DISPLAY-HINT "2d-1d-1d,1d:1d:1d.1d,1a1d:1d"
// field octets contents range
// ----- ------ -------- -----
UINT16 Year; // 1 1-2 year* 0..65536
UINT8 Month; // 2 3 month 1..12
UINT8 Day; // 3 4 day 1..31
UINT8 Hour; // 4 5 hour 0..23
UINT8 Minute; // 5 6 minutes 0..59
UINT8 Second; // 6 7 seconds 0..60 (use 60 for leap-second)
UINT8 DeciSec; // 7 8 deci-seconds 0..9
CHAR DUTC; // 8 9 direction from UTC '+' / '-'
UINT8 HUTC; // 9 10 hours from UTC* 0..13
UINT8 MUTC; // 10 11 minutes from UTC 0..59
// For example, Tuesday May 26, 1992 at 1:30:15 PM EDT would be
// 1992-5-26,13:30:15.0,-4:0
}
case 0x32 : //2911 4.1.15 "resolution" --> RFC1759
[Ret]
struct Resolution = FormatString("%ix%i %s",CrossFeedRes, FeedRes, IPPUnits(Units))
{
INT32 CrossFeedRes;
INT32 FeedRes;
INT8 Units;
}
case 0x33 : // "rangeOfInteger"
[Ret]
struct Range = FormatString("%i-%i",lower, upper)
{
INT32 lower;
INT64 upper;
}
default:
[Ret]
AsciiString(ValueLength) StringValue;
}
}
}